

Data used to train artificial intelligence (AI) models is becoming increasingly scarce. At least that’s what a study carried out by a group of institutions, including Epoch, University of Aberdeen, MIT and University of Tübingen, says, which warns that these resources are expected to be exhausted by 2026. Furthermore, high-quality linguistic and image data quality may follow the same path between 2030 and 2060. The predictions raise questions about the future of AI and its performance in favor of humanity.


The lack of high-quality data can hinder the development of new technologies, limit the learning capacity of tools, and lead to worse performance in tasks such as machine translation, speech recognition, and text generation. This scenario could have implications for vital areas such as healthcare, education and finance, which increasingly depend on AI to operate efficiently. Next, understand why high-quality data is important for the development of AI and find out whether these platforms may end in the near future.
What does the research say about data for training AIs?
The study highlights that data quality is fundamental to the success of any AI model. Accurate, relevant, ethical and appropriate data is essential for training robust and reliable models. However, collecting and curating requires considerable time and resources, making this task increasingly challenging.

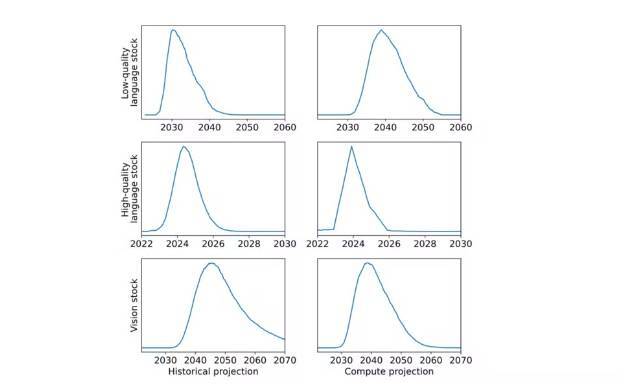
Additionally, the paper addresses the predicted depletion of high-quality data for training language models in the near future, highlighting the need to consider data efficiency and the search for new sources to support continued progress. The analysis also points to the importance of developing robust automatic metrics, improving the quality of data sets used in AI models.
Why is high-quality data important for artificial intelligence?
Data is the raw material that feeds and shapes AI systems. The use of high-quality information during the training of these platforms is essential to ensure the accuracy and reliability of the predictions and responses generated. Accurate data enables tools to offer correct answers and assertive predictions, reducing the risk of “hallucinations”.
When supplied with reliable information, AIs become more comprehensive, versatile and assertive in different contexts. The quality of the information learned also influences the ability of artificial intelligence to apply its knowledge in new situations, especially in critical applications, such as in the area of health or security, for example.
In addition to accuracy and reliability, the data used in AI training must also be secure, not containing sensitive information, such as personal or financial data. Ensuring ethics and data security also helps prevent models from reproducing biases or sensitive information that could harm or offend individuals and groups. This is what happened, for example, with Gemini Google, which had to pause image generation recently, after producing erroneous historical representations.
Is this the end of artificial intelligence models?
The future of AI may seem complex given challenges such as data scarcity and the spread of biased information. But that doesn’t mean this technology will go away. Progress in research and innovation continues to drive the development of new training techniques that circumvent obstacles like these. Collaborative action between governments and research institutions could be the key to finding solutions. This includes creating incentives for information sharing and investing in research aimed at improving the efficiency of AI models.


One promising possibility is the improvement of algorithms by AI developers, enabling more efficient use of available data. In the future, it is possible that models will be trained with less data, which would not only boost the efficiency of AI, but also contribute to reducing the environmental impact generated by this industry. Furthermore, there is an excess of content beyond the free online space that could be explored. Material from major publishers and offline repositories represents a potentially valuable source of learning.
Digital content protected by paywalls may also be made available in the future. A recent example is the initiative by News Corp, one of the largest owners of news content in the world, which announced content negotiations for AI developers. Collaborations with media companies have the potential to significantly expand the datasets available for training, driving innovation in the field of artificial intelligence.
Another way to ensure the longevity of AIs is efforts to improve the generation of synthetic data, that is, unlimited information created by computers that reproduce the characteristics and patterns of the real world. This content is generated by algorithms and computer simulations, using generative artificial intelligence technologies. This strategy not only increases the availability of material for AI training, but also offers an effective alternative for scenarios in which obtaining real data is limited or restricted due to privacy, security or cost issues.